

DB 단건 처리에서 배치 처리로 : 히스토리 서비스 처리량 개선 본문
요구 사항
우리 팀은 IoT 기기를 다룬다. 도어락의 문 열림 기록이나, 온습도계의 일간, 월간 온습도 변화 기록 조회 등, 기기의 상태 기록을 조회할 수 있는 기능을 제공한다. 이런 기능을 위해 ‘히스토리’ 서비스는 기기의 상태 이벤트를 수신하고, 기록해야 할 테이터를 필터링하여 DB에 적재하는 역할을 수행한다.
현재 히스토리 서비스에서 저장해야 하는 이벤트 양은 초당 초당 2600 ~ 2800건이다. 그리고 아래는 현재 히스토리 서비스 초당 처리량이다. 이벤트 유입량과 처리량이 크게 차이가 나지 않음을 알 수 있다. 지금까진 가까스로 처리되었지만, 지금보다 유입량이 조금만 더 많아지면, 유입량이 처리량보다 많아져 이벤트 유실이나 OOM이 발생하기 좋다.

우리 팀의 목표 요구치는 초당 6천 건의 저장이었다. 처리량이 그 정도는 벌어져야, 안정적으로 서비스 운영이 가능하다고 판단했다. 참고로 지금의 초당 3천 건의 처리량은, 이벤트 유입량이 초당 1700건 정도 발생했던 때에 만들어진 로직과 설정 값이다. 이런 배경에 히스토리 서비스의 처리량 개선을 시도했다.
가장 빠른 방법
문제를 풀기 위한 가장 빠른 방법은 단순히 저장을 위한 스레드 수를 늘리는 것이었다. 이벤트 브로커의 파티션 수를 늘려 여러 스레드(커넥션)에서 동시에 적재하는 것이다. 테스트해 보니 파티션 개수를 2.5배 늘려야 요구 처리량인 초당 6천 건의 처리량을 만들 수 있었다. 다만 이 서비스 하나만의 개선을 위해, 카프카 파티션 수 자체를 늘리는 것이 옳은 방법이라고 생각하지 않았다. 리소스 증설에만 기댄 문제 처리는 한계가 분명하다.

파티션 개수는 그대로 두고 DB 저장 로직 자체만 멀티 스레드 혹은 리액티브로 처리할 수 있을 것 같다. 이런 방법도 마찬가지로 확장할 수 있는 리소스 자원에는 한계가 있으며, 스레드 풀 관리를 잘못하는 경우 처리량이 밀리거나 OOM으로 이어질 수 있다. 만일 WAS단의 리소스가 무한하다고 가정하더라도, DB 단의 연산이 늘어나 CPU를 과도하게 사용하게 될 것이다. 결국 WAS의 리소스 문제를 미뤄, 데이터베이스의 리소스 문제로 이어진다.
사실 무엇보다 매번 이벤트가 수신될 때마다 DB를 접근하는 게 비효율적이라고 판단했다. 이벤트를 모아 Bulk insert를 사용하면 네트워크 통신 비용, 실제 클라우드 네트워크 트래픽 비용, DB의 연산량, 커넥션 점유 경합에 개선이 있을 것이라는 생각이었다.
배치 처리
이벤트 수신 시 저장할 큐, 배치 처리를 위한 스케줄러를 구현하였다. 카프카에서 이벤트를 수신하여, Thread-safe 한 큐에 저장한다. 일정한 시간 간격으로 큐를 비우고, 배치 사이즈만큼씩 bulk insert를 처리한다. 큐에 이벤트를 쌓는 스레드와 큐에서 이벤트를 처리하는 스레드를 분리하도록 설계했다.
배치 스케줄링 주기가 데이터 삽입 시간에 영향받지 않도록
스케줄러는 주기적으로 수행하되, DB 쿼리 자체는 비동기로 처리한다. 동기로 처리하는 경우, 한번 쿼리가 느려지면 다음 스케줄링이 늦어지고, 큐에 또 많은 데이터가 쌓이게 되어 악순환이 반복된다. 비동기로 처리하여, DB 수행 시간에 배치 스케줄링 주기가 영향받지 않도록 한다.
큐 사이즈 지정, DLQ
DB에 저장하는 처리량보다 유입량이 많아 이벤트가 큐에 계속 쌓이고 늘어나면 OOM으로 이어질 수 있다. 큐가 저장할 수 있는 사이즈를 명확하게 해 줘, 큐의 메모리가 OOM까지 늘어나는 상황을 피했다. 대신 큐 사이즈를 넘어선 이벤트에 대한 대비가 필요하다. 큐 저장에 실패한 이벤트를 DLQ에 전달하고 재시도 / 알람 / 로깅을 처리한다. 이벤트 수신 스레드와 Dead letter 처리 스레드를 분리하여, 이벤트 수신 스레드에서 유실 대비를 위해 블록킹 되어 수신이 느려지는 상황을 피한다.

안전하게 종료하기
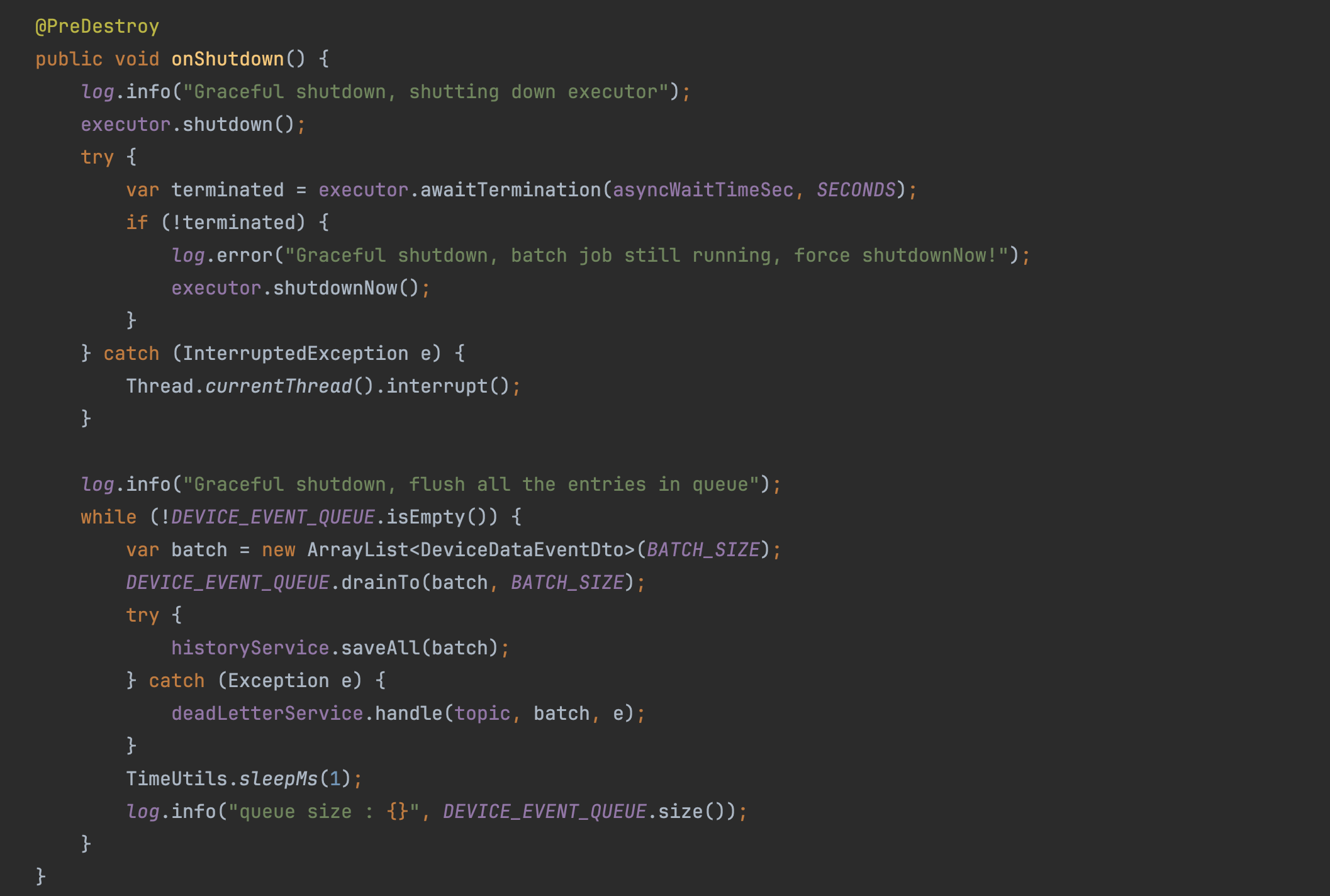
서버가 다운될 때, 현재 큐에 적재되어 있는 이벤트와 작업 중인 스레드를 안전하게 정리하기 위한 고민이 필요하다.
새로운 자원 유입 막기
남아있는 것을 정리하기 전에, 우선 새로 인입되는 것을 막아야 한다. 내 상황에선 '1. 큐에 이벤트가 추가로 수신되는 것이 없는지', '2. 새로운 배치 작업이 추가로 수행되는 것은 없는지', 확인이 필요했다. Spring boot의 Graceful shutdown 발생 시, @KafkaListener를 통한 이벤트 수신이 종료되고, @Scheduled로 새로운 작업이 수행되지 않음을 확인할 수 있었다.
작업 중인 스레드 대기하기
새로 추가되는 이벤트, 배치 작업이 없는 것을 확인했으니, 이제 남은 이벤트와 작업을 정리한다. 우선 비동기로 처리되고 있는 작업을 대기한다. 아래 코드에서 'asyncWaitTimeSec' 변수로, 현재 진행 중인 비동기 작업 종료를 대기하는 시간을 지정했다. 이때 이 값은 Spring boot의 Graceful Shutdown 대기 시간보다 작고, DB 쿼리 수행 Timeout 시간보다는 크게 설정해야 할 것이다.
큐에 남아있는 이벤트 처리
비동기 작업 스레드에 대한 정리가 끝나면, 현재 큐를 전부 비울 때까지, Bulk insert 반복한다. 이때 큐의 모든 데이터를 한 번에 처리하지 않고, Batch size로 구간을 나눠 작업을 반복한 이유는, 큐에 남은 데이터가 많아 쿼리 자체가 너무 느리거나, DB 커넥션 관리에 방해가 되지 않기 위함이다.
테스트
Stage 환경에서 테스트를 진행했다. 처리량 확인을 위해 실제보다 많은 이벤트를 인위적으로 만들어 유입시켰다. 그 외 카프카 파티션 수나 DB 리소스 등은 기존과 동일하게 구성하였다. 개선한 배치 작업이 안정적으로 처리할 수 있는지 확인한다.
배치 사이즈 조정
다른 기능 개발과 달리, 이번에는 배치 사이즈나 이벤트 적재 속도, 쿼리 실행 속도, DB 리소스 등 봐야 할 매트릭과 이에 따라 조정해야 하는 값들이 많았다. 특히 배치 주기와 사이즈에 따른 큐의 이벤트 유입 대비 처리 속도가 매우 중요했다. 배치 주기와 사이즈가 적절하지 않으면 DB 쿼리 시간이 길어져 커넥션 점유가 커지거나, 큐의 이벤트 유입 대비 처리가 늦어 이벤트가 처리가 지연되고 큐를 모두 다 차지하는 꼴로 이어질 수 있을 것이다.
조정한 값으로 수행한 테스트 결과는 목표했던 초당 처리량 6천 건을 훌쩍 넘은 수치였다. 이벤트 적재 큐 사이즈도 크게 증가하지 않았고, 유입량 대비 안정적인 처리량을 보였다. DB 리소스 사용량도 문제 되지 않음을 확인했다.

Graceful shutdown으로 종료 시점에서의 큐 비우기도 문제없었다. 아래 로그에서 SIG_TERM이 수신되고, 배치 처리 중이던 비동기 테스크들이 정상 종료되고, 큐에 남아있던 이벤트들이 두 번의 추가 배치 처리 이후에 적절히 제거되었음을 확인할 수 있었다.

한 일주일 정도 Stage 환경에서 큐 사이즈와 처리량, Kafka 이벤트 수신 정도에 문제가 없는지, DB 리소스 매트릭과 Slow query 발생은 없었는지 확인하는 시간을 가질 생각이다.
MongoRepository의 saveAll 동작 방식
처음 개발을 마치고 테스트했을 때, 처리량 개선이 크지 않았다. 쿼리 로그를 확인하니, 예상했던 Bulk insert가 아니라 매 엔티티마다 Insert 쿼리가 나가고 있었다. MongoRepository의 saveAll은 저장하려는 모든 엔티티의 id가 없는 상황에서만 bulk insert가 진행되는 것을 공부할 수 있었다. 기존 엔티티를 매핑하던 로직에서 무의미하게 지정했던 id를 제거하는 것으로, 의도대로 bulk insert를 처리하였다.

정리
이슈 : 기기 상태 내역 DB 저장 처리량 개선
작업 :
- 기기 상태 이벤트 수신 후 단건 저장하던 로직을, 배치 Bulk insert로 변경
- 프로세스 종료 시점에, 현재 진행 중인 배치 작업과 큐에 남아 있는 이벤트 정리
- 큐에 이벤트 유입량과 처리량을 기반으로, 적정 배치 사이즈, 주기 값 조정 테스트
결과 :
- 초당 3300개의 처리량에서 20000개 이상의 처리가 가능하도록 처리량 개선
- 네트워크 트래픽 비용, DB 연산량, 커넥션 점유 경합 개선 예상
'KimJinHwan > Project' 카테고리의 다른 글
| OOM 문제 해결 : 스레드 풀, 요청량이 처리량을 넘어설 때 (0) | 2025.10.09 |
|---|---|
| 팀 인프라 개선 프로젝트 : AWS 전환, 컨테이너화, IaC, 배포 정책 등 (0) | 2025.10.06 |
| 동시성 문제 처리 : 포인트 차감과 보상 사이, 포인트 부족 현상 (4) | 2025.09.08 |
| 논 블록킹 처리 : 이벤트 처리량, 스레드 사용량 개선 (0) | 2025.09.04 |
| 캐시 도입 : 이벤트 파이프라인 처리량 높이기 (1) | 2025.08.28 |