
두 번의 갱신 분실 문제와 락 본문
두 번의 갱신 분실 문제 발생
유저가 파일을 업로드하면 사용 가능 공간을 확인하고 현재 사용 중인 공간을 업데이트한다. 업로드 동시 요청이 발생하는 경우, 마지막에 수행되는 커밋의 결과만 반영되어 의도하지 않은 값이 저장된다. 이렇게 여러 트랜잭션에서 동일한 데이터를 동시에 수정하려할 때, 마지막으로 수행한 수정만 반영되는 경우를 두 번의 갱신 분실 문제라고 한다.
# 두개의 스레드에서, 동시에 5MB 파일을 업로드할 때
Thread 1 - 현재 스토리지 사용량 조회 0MB
Thread 2 - 현재 스토리지 사용량 조회 0MB
Thread 1 - 스토리지 사용량 기록 5MB
Thread 2 - 스토리지 사용량 기록 5MB
낙관적 락
낙관적 락은 조회와 수정에 버전을 함께 확인하여 충돌 여부를 파악한다. 엔티티 버전을 함께 기록하고, 수정시 조회의 엔티티 버전과 동일한지 확인하는 것으로 충돌을 감지한다.
SELECT cur_usage, version FROM storage_usage WHERE user_id = 1;
UPDATE storage_usage SET cur_usage=5, version = 2 WHERE user_id=1 AND version = 1;
낙관적 락은 트랜잭션이 커밋될 때 버전을 확인하고 충돌시 예외를 발생시킨다. 그래서 예외를 핸들링(주로 재시도)하기 위해선 반복의 범위를 `@Transactional` 의 범위보다 크게 해야 한다.
기본 전파 방식 Required 는 기존 트랜잭션에 편입되어 트랜잭션 범위를 파악하기 까다롭다. 전파 방식을 Required_New로 변경하면 재시도 처리가 간결해지긴 할텐데 커넥션 사용 개수가 늘어나고 이전 트랜잭션과의 원자성이나 1차 캐시 적용 등 다른 고민이 필요하다. 일단은 전파 방식을 변경하는 것은 피했다.
재시도 처리를 위한 코드가 지저분했고, 충돌시 재시도로 DB 엑세스 횟수가 늘었다.
비관적 락
그에 비해 비관적 락은 코드가 명확하고 관리 포인트가 적다. 다만 조회 성능이나 데드락을 조심해야 했다. 문제가 되었던 로직에선 조회에 공유락 사용하면 데드락이 발생했고, 배타락을 사용하면 데드락 여지가 없었다.
start transaction;
select * from storage_usage where user_id=1 for update;
update storage_usage set limit_as_byte=100, usage_as_byte=28 where user_id=1;
commit;
위는 비관적 락을 사용했을 때의 해당 로직에서 발생하는 쿼리 수순이다. Mysql 은 락을 인덱스에 건다. 조회에 배타락을 사용한 위 쿼리에서도 인덱스의 사용에 따라 테이블 락이 걸릴 수도, 로우 락이 걸릴 수도 있다.
현재 조회 쿼리에서 조건에 사용되는 user_id 에 인덱스를 생성하여 조회에 Table lock 이 아닌 Row lock을 사용할 수 있었다. 즉 충돌 시 사용자 별 Lock으로 격리된다.
한 사용자가 동시에 업로드 하는 상황에서, 본인의 업로드가 순차적으로 처리되기 위한 대기는 감수할만 하다고 생각했다.그래서 비관적 락을 사용했고, 사용자별 대기로 동시성 문제를 처리했다.
비관적 락의 DB 커넥션 점유 문제
사용자별 락이기에 본인의 충돌 요청만 대기하면 될 것 이라고 생각했다. 부하 테스트를 진행했고 대기 중에 CP의 커넥션을 점유하고 있다는 사실을 놓쳤음을 확인했다.

위 그림처럼 조회시 락으로 커넥션이 모두 점유된다면, 스레드는 HandOffQueue 를 Polling 커넥션을 획득하기 위한 대기가 필요해진다. 한 사용자가 CP를 독점한다면 결국 다른 사용자들도 커넥션을 독점한 사용자의 요청이 순차 처리되길 기다리는 상황이 발생하는 것이다.
단순히 DB CP를 늘리면 어떨까. DB는 결국 Disk I/O를 쓰기에 너무 많은 커넥션은 Disk 경합 측면에서 좋지 않다고 한다. 또 커넥션과 함께 늘어난 컨텍스트 스위칭 비용이 발생할테니 커넥션 개수만 늘리는게 능사는 아니다.
HikariCP 커넥션 점유 과정
1. Thread local 에서 이전 사용했던 커넥션(threadList)을 확인하고 사용 가능 상태인 커넥션이 있다면 이를 사용한다.
2. 전체 커넥션(shared_list)에서 사용 가능한 커넥션이 있다면 이를 사용한다.
3. 사용 가능한 커넥션이 없다면 HandsOffQueue에서 커넥션 반납을 대기한다.
4. Connection_timeout 시간을 넘어서면 대기를 포기하고 예외를 알린다.
5. 커넥션 사용을 마쳤을 때 HandsOffQueue에 대기 중인 스레드가 있다면 Queue에 커넥션을 반납한다.
6. 대기 중인 스레드가 없다면 커넥션의 점유 상태를 변경하고 이전 사용 기록(threadList) 에 추가한다.
레디스를 이용한 분산락 처리
Redis 의 SETNX 명령어는 Key 값이 존재하는지를 확인하고 존재하지 않는다면 SET 을 수행한다. "키 조회와 키 생성"이 한 연산으로 처리되는 원자적 연산을 사용하여 키의 여부를 락의 점유 여부로 생각할 수 있다.
public void aquire() throws TimeoutException {
var locks = redisTemplate.opsForValue();
while (true) {
if (locks.setIfAbsent(LOCK_KEY, true, lockTtl, TimeUnit.MILLISECONDS)) {
return;
}
Thread.sleep(1);
}
}
위와 같은 스핀-락은 반복 간격(N)이 너무 작으면 불필요한 Redis 액세스가 늘고, N이 너무 크면 대기 시간이 늘어난다. 무엇보다 대기하는 대기자가 많아질 수록 레디스 액세스가 그 수만큼 배가 되고, 실제로 부하테스트 중에 레디스 커넥션 오류를 경험했다.
Pub/Sub 방식으로 액세스 횟수 개선
Redisson 은 레디스 Pub/Sub으로 락을 효율적으로 구현한다. 락 사용을 마치면 대기자들에게 알려 점유를 시도하게 한다. 락 점유 여부 확인을 반복 하지 않을 수 있으니 액세스 횟수가 개선된다.
그렇다고 '락 점유 회수 == 액세스 점유 횟수'는 아니다. 또 점유자들의 점유 순서에 맞춘 락 점유 순서를 보장하지 않는다. 아마 Redis의 기본 Pub/Sub 방식을 따라 Publish 시 모든 대기자들에게 일괄 분배하고, 대기자들은 액세스 -> 점유의 경합을 하는 식으로 구현되어 있어서가 아닐까 생각해본다. 따라서 티켓 대기열처럼 꼼꼼한 순차 처리가 필요한 상황에선 주의가 필요하다.
public void acquire() throws TimeoutException {
try {
var locks = redissonClient.getLock(LOCK_KEY_NAME);
if (!locks.tryLock(LOCK_WAIT_TIME, LOCK_TTL, TimeUnit.MILLISECONDS)) {
throw new TimeoutException();
}
} catch (InterruptedException e) {
throw new IllegalArgumentException("Thread interrupted");
}
}
사용자 별 락 처리
사용자별 락을 달리하기 위해 Redis 키를 사용자 별로 나눴다. 각 사용자마다 해당 유저가 현재 addUsage() 를 사용 중인지 확인할 수 있는 값을 레디스에 담는 것이다. 다만 이렇게 사용자와 키가 1:1을 이룬다면, 너무 많은 키가 필요해 공간 활용에 비효율적일 것이다. 사용자 id 를 Hash 처리하여 락 키로 사용했다. 해시 값이 충돌되는 사용자끼리는 요청이 몰리면 서로를 대기하게 된다.
var lockKeyName = LOCK_KEY_PREFIX + getIdHash(userId);
var locks = redissonClient.getLock(lockKeyName);
트랜잭션 범위
무엇보다 중요한 것은 락의 범위가 트랜잭션의 범위보다 커야 한다는 것이다. 트랜잭션의 범위보다 작아 트랜잭션 처리 도중 락이 풀리면 그 사이에 발생한 조회/업데이트로 다시 두번의 갱신 분실 문제가 발생할 것이다.
@Transactional 의 기본 전파 방식 Required 를 사용하고자 한다면 트랜잭션의 최초 시작점을 추적해야 할 것이다. 전파 방식을 Required_new 로 변경하여 트랜잭션의 범위를 명확하고 Lock으로 감싸, 락 범위가 트랜잭션 범위보다 더 클 수 있도록 보장할 수 있다.
@UserLock(key = "userId")
@Transactional(propagation = Propagation.REQUIRES_NEW)
public Long upload(long userId, long albumId, ResourceKey resourceKey) {}
Picup에서는 `@Transactional`의 메서드 호출 깊이가 깊지 않다. Service 코드가 크지 않아 트랜잭션의 시작이 쉽게 확인되고 명확하다.- 특히 전파 방법을 바꾸게 되면 커넥션 점유 개수가 늘고, 기존 트랜잭션과 별도 트랜잭션의 데이터 변경을 고민하게 된다.
예를 들어 두 트랜잭션간 원자성 처리나 1차 캐시 여부 등 데이터의 변화를 계산해야 하는 것이 관리 포인트라고 생각했다. 그래서 전파 방식 변경은 최대한 미루고 싶었다.
userLockService.<Long>isolate(
userId,
() -> pictureFacadeService.upload(userId, albumId, resourceKey)
);
일단은 전파 방식 변경 없이 트랜잭션의 최상단 메서드(upload)를 직접 락 범위 안에서 호출하는 식으로 처리했다. 당장은 깔끔하고 관리 포인트도 적다고 생각하는데, 코드가 커지고 트랜잭션의 범위를 찾는게 어려워지면 다시 그때에 맞는 좋은 풀이를 고민해야 할 것 같다.
테스트 코드
ExecutorService 를 사용하여 ThreadPool 을 만들고 문제가 되었던 사용량 업로드 로직을 테스트했다. CountDownLatch 로 모든 스레드 실행 종료 후 결과를 확인할 수 있도록 Blocking 한다.
@DisplayName("동시 업로드 동시성 문제를 테스트한다.")
@Test
public void uploadConcurrentRequest() throws InterruptedException {
var executorService = Executors.newFixedThreadPool(CONCURRENT_COUNT);
var countDownLatch = new CountDownLatch(CONCURRENT_COUNT);
for (int i = 0; i < CONCURRENT_COUNT; i++) {
executorService.execute(() -> {
try {
storageUsageService.addUsage(userId, FILE_SIZE);
} finally {
countDownLatch.countDown();
}
});
}
countDownLatch.await();
assertThat(FILE_SIZE * CONCURRENT_COUNT)
.isEqualTo(storageUsageService.getUsage(userId).getUsageAsByte());
}
요청 테스트
100개 씩 업로드 요청을 수행하는데 그중 50개는 한 유저에, 나머지 50개는 랜덤하게 선택된 유저에 이미지를 업로드한다. 이를 30초간 반복한다. 테스트는 k6 를 사용했다.
한 사용자에게 요청의 절반을 몰리게 한 것은 사용자 별 락이기 때문에 한 사용자에 요청이 몰렸을 때도 문제 없이 처리할 수 있는지를 보고자 했다. 의도한대로라면 50개씩 요청을 수행한 1명을 제외하곤 사용자별로 모두 락에 의한 대기없이 수행되어야 한다.
export let options = {
scenarios: {
targetUserUploadScenario: {
executor: 'constant-vus',
exec: 'targetUserUploadScenario',
vus: 50,
duration : '30s'
},
randomUserUploadScenario: {
executor: 'constant-vus',
exec: 'randomUserUploadScenario',
vus: 50,
duration : '30s'
}
}
};
30초 동안 총 2877 개의 요청이 전송되었고 모두 200으로 정상 응답되었다. 참고로 같은 테스트에서 레디스 스핀-락을 사용한 경우에선 예외가 발생했었다. 락 확인 반복 주기를 너무 짧게해 레디스에서 정상 처리를 못했었다.
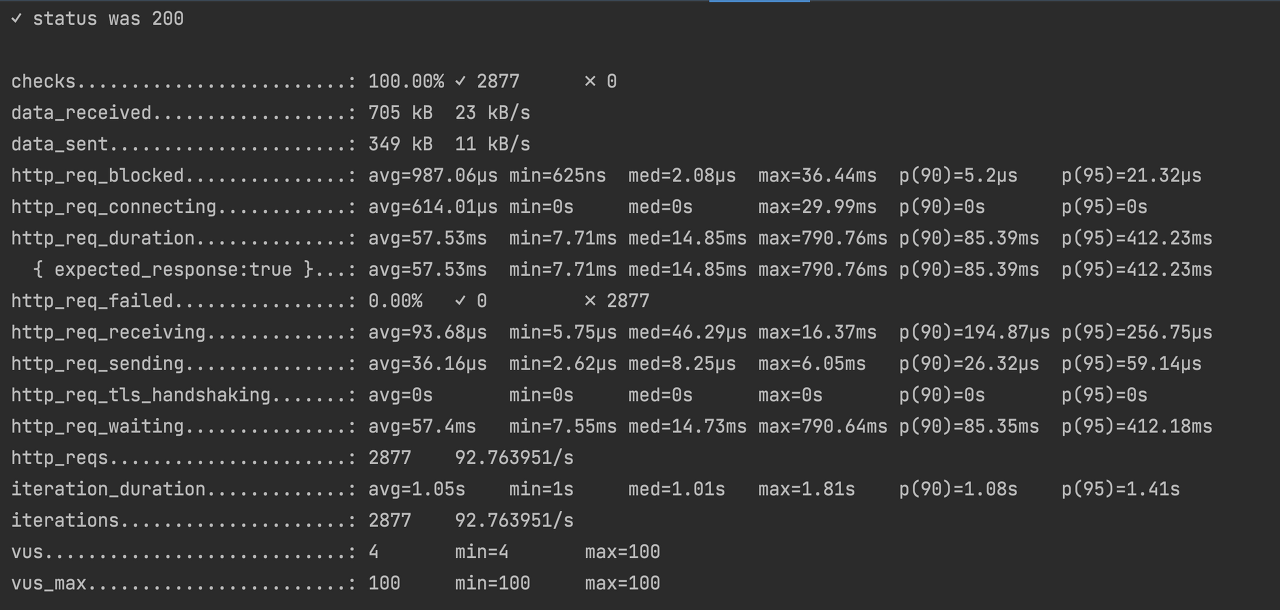
동시성 문제는 발생하지 않았다.
사용자 사용량과 사진 업로드 데이터가 의도한 대로 저장되었다.

댓글 답변 - 1. HikariCP 상태를 확인하는 방법
1. HikariCP 로그 출력
logging.level.com.zaxxer.hikari=TRACE
logging.level.com.zaxxer.hikari.HikariConfig=DEBUG
위를 Application 설정에 추가하는 것으로 Pool 상태를 확인할 수 있다. 30초에 한 번씩 아래와 같이 총 커넥션, 현재 사용 중인 커넥션, 놀고 있는 커넥션, 대기 중인 커넥션이 로그로 남는다.
2024-01-26T21:34:28,983 DEBUG [HikariPool-1 housekeeper] c.z.h.p.HikariPool: HikariPool-1 - Pool stats (total=10, active=0, idle=10, waiting=0)
2. HikariPoolMXBean 으로 직접 로깅
JMX MBean for HikariCP 를 사용하여 직접 로그를 출력할 수 있다.
(brettwooldridge - MBean (JMX) Monitoring and Management
spring.datasource.hikari.register-mbeans=true
spring.datasource.hikari.pool-name=pool-name
MBean 등록을 true 로 허용하고, hikari pool name을 지정한다.
@Bean
public HikariPoolMXBean poolProxy() throws MalformedObjectNameException {
MBeanServer mBeanServer = ManagementFactory.getPlatformMBeanServer();
ObjectName objectName = new ObjectName("com.zaxxer.hikari:type=Pool (pool-name)");
return JMX.newMBeanProxy(mBeanServer, objectName, HikariPoolMXBean.class);
}
그리고 HikariPoolMXBean 을 빈으로 등록하면 된다. 아래 빈 등록 코드에서 pool-name 은 설정한 pool 이름으로 수정한다. HikariPoolMXBean 의 메서드로 총 커넥션, 현재 사용 중인 커넥션, 놀고 있는 커넥션, 대기 중인 커넥션를 얻을 수 있다.
@Autowired
HikariPoolMXBean hikariPoolMXBean;
public void foo() {
logger.info("\n"
+ "activeConnections : " + hikariPoolMXBean.getActiveConnections() + "\n"
+ "idleConnections : " + hikariPoolMXBean.getIdleConnections() + "\n"
+ "waitingConnections : " + hikariPoolMXBean.getThreadsAwaitingConnection()
);
}
댓글 답변 - 2. JPA가 아닌 JdbcTemplate 으로 낙관적 락
댓글에서 Mybatis 를 사용하시는데 테스트가 원활하지 않아, JPA가 고립 수준을 바꾸는 등 다른 처리가 있는지 질문해 주셨다.
JPA의 역할은 수정 시 Transaction이 커밋될 때 이전 조회에서 사용한 version 을 where 조건에 추가, version을 업데이트하는 것이 전부이지 않을까 생각한다.
혹시 빠트린건 없을지 JPA 에서 벗어나 JdbcTemplate 으로 버전 정보를 이용한 동시성 문제 인지를 구현해 보았다.
@Transactional(isolation = Isolation.REPEATABLE_READ)
public void updateWithVersion(long userId, long curUsage, LocalDateTime curVersion) {
var updateRow = jdbcTemplate.update(
"UPDATE storage_usage " +
"SET cur_usage = " + curUsage + ", version = " + (curVersion +1) + " " +
"WHERE user_id = " + userId + " AND " + "version = " + curVersion
);
if(updateRow == 0) {
throw new IllegalArgumentException("OptimisticLockingFailureException");
}
}
'Architecture > Application' 카테고리의 다른 글
| 트랜잭션 아웃 박스 패턴 : 이벤트 발행과 DB 트랜잭션 원자성 유지하기 (0) | 2024.06.01 |
|---|---|
| RepeatableRead 에서 발생할 수 있는 동시성 문제와 락 (8) | 2024.01.10 |
| Future 를 활용한 비동기 이미지 비동기 업로드 흐름과 시연 (0) | 2023.11.28 |
| 도메인 이벤트를 이용하여 의존성 분리 연습 (4) | 2022.01.12 |
| Scheduler 적용 배경 / 스레드 풀과 비동기 처리 (2) | 2021.10.03 |