
Nginx 엑세스 로그로 응답 시간 모니터링 본문
0. 배경
WAS 전면에 Nginx 를 두고 TLS, HTTP2.0, RateLimit, 정적 자원 호스팅 등 요청을 전처리하고 있다. 이 Nginx 의 메트릭을 모니터링하려고 한다. WAS 의 응답 시간, 요청 수뿐만 아니라, Nginx가 전면에서 처리하는 응답 시간, 요청 수, 리다이렉트 수가 궁금했다.
1. nginxlog-exporter
처음에는 Nginx가 기본적으로 제공하는 exporter 를 사용했었다. nginxinc/prometheus-exporter 에서 알 수 있듯, 해당 exporter 에서 제공하는 메트릭은 충분하지 않았고, 응답 시간을 포함한 원했던 메트릭은 대부분 Nginx plus 에서만 제공했다.
nginx 의 액세스 로그에 응답 시간을 남기는 설정이 있음을 미리 알고 있었다. 그래서 앞선 nginx에서 제공하는 exporter에 더해 액세스 로그를 파싱하면 어떻게든 응답 시간을 포함한 원하는 메트릭들을 만들 수 있을 것도 같았다. 이런 방향으로 다른 경험기들은 없는지 검색했고, 액세스 로그를 파싱하여 prometheus exporter 를 만들어둔 오픈 소스 툴을 찾을 수 있었다.
저장소 : https://github.com/martin-helmich/prometheus-nginxlog-exporter
2. 로그 포맷 수정
우선 Nginx 의 로그 포맷을 확인한다. 로그 포맷에 $request_time 을 추가해야 한다. request_time 은 클라이언트 요청의 첫 바이트를 읽는 시점부터, 응답의 마지막 바이트를 전달하는 시점까지의 시간을 초로 기록한다. Nginx의 기본 로깅 내용이 아니므로 포맷을 수정하여 로그에 처리 시간이 있도록 한다.
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$request_time" "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
keepalive_timeout 65;
include /etc/nginx/conf.d/route-blog.conf;
}
3. log exporter 설정
prometheus exporter 는 nginx 가 남긴 액세스 로그를 읽고 파싱하여 메트릭 정보를 얻어낸다. 그 정보를 바탕으로 http api 를 열어두면 prometheus 가 이를 스크랩하여 파일로 저장해 두고, 그라파나에서 쿼리 할 때 그 쿼리에 해당하는 값을 반환하여 대시보드를 그리게 된다.
설정 파일에선 이 exporter 를 설정한다. 아래 예시를 읽으면 4040으로 포트로, "0.0.0.0" 으로 모든 ip 주소로부터의 접근을 허용하고, api path는 /metrics 로 한다.
namespace 의 내용이 중요하다. namespace 의 name 을 Prefix 로 프로메테우스 메트릭 이름이 생성된다. 예를 들어 아래 예시의 nginx 라면 `nginx_http_response_time_seconds_sum` 과 같이 메트릭이 생성된다. format은 액세스 로그의 포맷을 그대로 적어줘야 한다. 그래야 exporter 가 정확하게 로그를 파싱할 수 있고, source.files 에서 액세스 로그의 파일 위치를 정확하게 기입한다.
listen:
port: 4040
address: "0.0.0.0"
metrics_endpoint: "/metrics"
consul:
enable: false
namespaces:
- name: nginx
format: "$remote_addr - $remote_user [$time_local] \"$request\" $status $body_bytes_sent \"$request_time\" \"$http_referer\" \"$http_user_agent\" \"$http_x_forwarded_for\""
source:
files:
- /var/log/nginx/access.log
4. Exporter 실행
docker 컨테이너로 exporter를 실행할 것이다. 내 경우에는 글 작성 시점인 최신 버전인 1.11의 amd64 를 사용했다. 프로젝트의 GHCR 에서 다양한 버전과 arch 별 이미지를 선택할 수 있다.
앞서 설정한 설정 파일과 nginx 액세스 로그를 volume으로 포함시켜 준다. 이를 적용하려면 './prometheus-nginxlog-exporter -config-file /path/to/config.hcl' 를 입력해줘야 하고, command 에 이를 추가하여 설정 파일을 등록시켰다.
version: '3'
services:
nginx-log-exporter:
image: ghcr.io/martin-helmich/prometheus-nginxlog-exporter/exporter:v1.11-amd64
volumes:
- ~/dev/data/nginx:/var/log/nginx
- ./exporter/prometheus-nginxlog-exporter.yaml:/config/prometheus-nginxlog-exporter.yaml
command:
- -config-file
- /config/prometheus-nginxlog-exporter.yaml
ports:
- "4040:4040"
extra_hosts:
- "host.docker.internal:host-gateway"
5. 그라파나, 프로메테우스 설정
프로메테우스에 exporter 의 metrics api 를 scrap target 으로 등록하면 설정은 끝이다.
scrape_configs:
- job_name: 'nginxlog-exporter'
static_configs:
- targets: [ "${exporter_ip}:4040" ]
제작자가 추천하는 쿼리는 다음과 같다. 또는 이미 만들어진 대시보드를 커스텀해도 좋다. 개인적으로는 grafana/dashboards/15947 를 추천한다. 단, 쿼리의 메트릭 이름은 앞서 설정한 namespace 의 name 을 prefix 로 따른다는 것을 유의한다.
Average response time
: sum(rate(nginx_http_response_time_seconds_sum[5m])) by (instance) / sum(rate(nginx_http_response_time_seconds_count[5m])) by (instance)
Requests per second
: sum(rate(nginx_http_response_time_seconds_count[1m])) by (instance)
Response time (90% quantile)
: nginx_http_response_time_seconds{quantile="0.9",method="GET",status=~"2[0-9]*"}
Status codes per second
: sum(rate(nginx_http_response_size_bytes[5m])) by (instance)
6. 부하 테스트
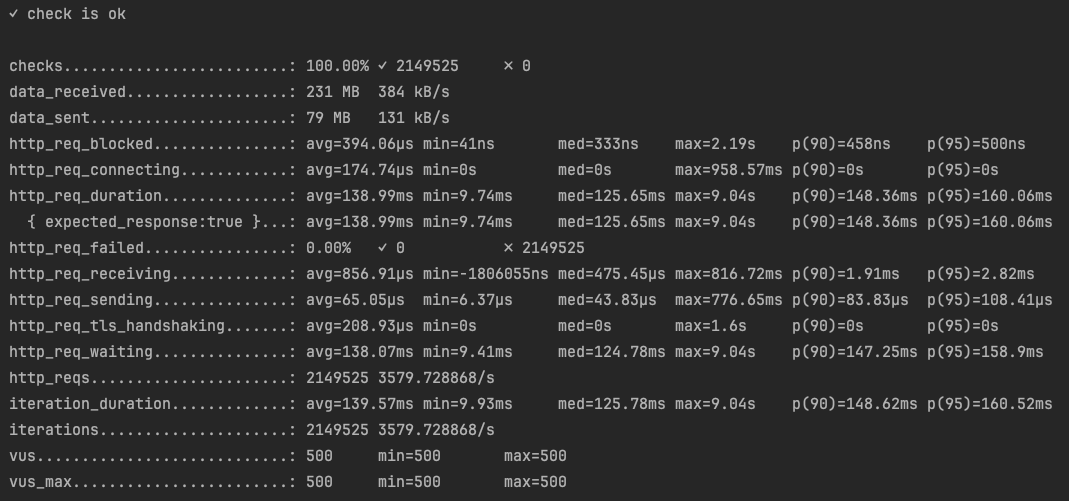
설정한 액세스 로그 기반의 모니터링을 테스트하기 위해 K6 를 이용해서 10분 동안 500명의 Vus 로 WAS 에 요청했다. http req duration 을 살펴보면 평균 138ms, 상위 95%의 응답이 160ms 으로, 목표했던 200 ms 안에 들어왔다.
(가장 오래 걸리는 응답이 9 초인 부분이 걸리는데, 꼭 부하테스트가 아니더라도 가끔 5~10초 사이의 응답이 발생하는 것을 경험했었다. TLS handshake 로 예상하고 있긴 한데, 당장은 감이 오지 않아 이후에 확인할 생각이다.)
모든 요청은 Nginx 를 먼저 진입 후 WAS 에 라우팅, 다시 WAS 의 응답을 Nginx 가 받아 사용자에게 반환하기에 두 곳에서의 응답 모니터링의 양상은 비슷해야 하고, 이를 바탕으로 새로 추가한 Nginx 모니터링을 테스트할 수 있었다.
대시보드의 상황은 아래와 같다. 좌측은 Spring boot actuator 에서 추출한 WAS의 평균 응답 시간과 1분당 요청 수, 우측은 Nginx 의 Access log 에서 추출한 평균 응답 시간과 1초당 요청 수이다. 양상부터 값까지 모두 유사하고, WAS의 응답을 받아 전달하는 Nginx 에서 약간이나마 조금 더 긴 응답 시간을 제대로 갖고 있음을 볼 수 있다.
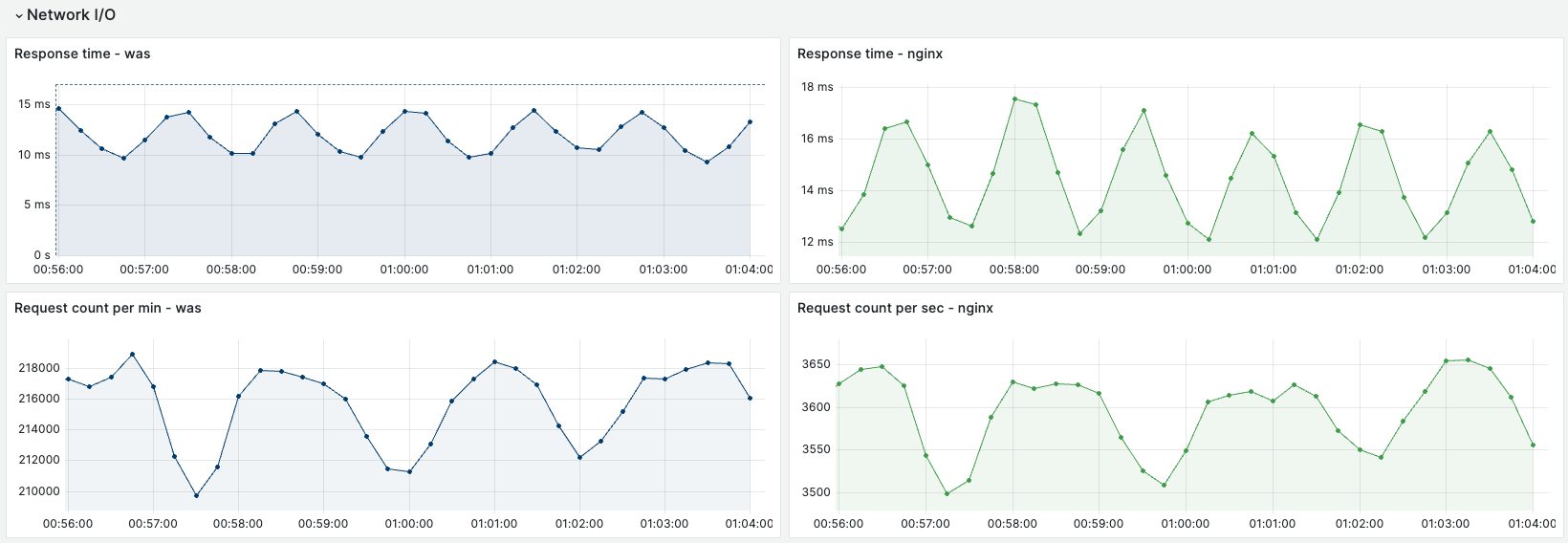
K6에서 표시하는 응답 시간과는 차이가 있다. 부하테스트 결과의 평균 응답 시간은 136ms 인데 반해 모니터링된 응답 시간은 10 ms ~ 18ms 까지다. 모니터링에 사용되는 응답 시간은 사용자 - 서버 사이의 네트워크 시간을 제외하고, 서버에 진입된 요청의 시작점부터 서버에서 나가는 응답의 끝점까지 이기 때문이다. 요청이 사용자로부터 언제 출발했고, 반환한 응답이 사용자에게 언제 도착했는지는 모른다.
7. 브라우저 waterfall / Http 2.0
브라우저에서 배포한 블로그 메인 페이지를 호출하면 어떤 waterfall 을 갖는지 확인해 본다. 맨 위의 html 파일을 응답받는데 오래 걸리고, 그 이후 js, css 파일 요청-응답, js 로 페이지를 그릴 때 필요한 api 요청들이 이후에 처리되게 된다.

여기서 회색은 브라우저의 커넥션 대기, 노란색은 TCP 커넥션을 위한 3way handshake 로 그 시간은 당장 내가 튜닝할 거리 밖이라 판단했다. 다만, http/1.1 을 사용하기 때문에 한 커넥션 안에서 여러 요청 (index.js, index.css) 를 처리하여 handshake 를 줄이지만, HOL blocking 문제로 index.js 의 응답 시간에 따라 index.css 요청에도 지연이 발생하고 있다.
또, 그 아래 여러 API 동시 요청을 위해 커넥션을 더 수립하고 있는데, Handshake 에 시간이 필요할뿐더러, 브라우저가 동시에 수립할 수 있는 커넥션 개수는 6개로 한정되어 있기에 개선의 여지가 있다고 생각했다.
아래는 HTTP 2.0 을 적용한 이후 같은 요청에 대한 waterfall 이다. TCP 커넥션은 한번만 일어나 handshake 비용과 커넥션 사용을 줄이고, index.js 와 index.css 에서 HOL bloking 문제가 개선된 것을 볼 수 있다. 또, 이후에 코드 추가가 있었던 index.html, index.js 파일을 제외하고 전체적인 응답 사이즈도 줄었는데, 이는 HTTP 2.0 에서 헤더 압축과 중복 제거가 일어나서로 가능한 일임을 추측해 본다.

Http 2.0 의 Server push 로 index.html 파일과 필요한 js, css 를 함께 전달하는 것을 고려했었는데 Nginx 에선 1.25.1 부터, Chrome과 다른 대부분의 브라우저들에서도 오히려 성능 저하로 더 이상 http 2.0의 server push 를 지원하지 않아, 적용하지 않았다.
chrome : https://developer.chrome.com/blog/removing-push?hl=ko
nginx : https://nginx.org/en/docs/http/ngx_http_v2_module.html
'Architecture > Infrastructure' 카테고리의 다른 글
| 쿠버네티스 배포 : 롤링 업데이트 동작 흐름과 무중단 처리 (0) | 2024.05.31 |
|---|---|
| CDN URL 암호화 : CloudFront signed url (1) | 2024.04.10 |
| Nginx 요청 호출 수 제한과 접근 가능 IP 제한 (0) | 2023.12.17 |
| Mysql Multi source replication, 백업 데이터 중앙화 (0) | 2023.11.18 |
| Mysql Replication, DB 부하 분산 (0) | 2023.11.05 |